
PHP 에서 대용량 데이터를 처리하는데에 있어서 푸시 메시지를 보낼때 큐를 사용한다던가
기존 쿼리가 너무 좋지 않아 쿼리 리팩토링을 한다던가..
는 실제로 접해봐서 사용해 보긴 했는데 (푸시 메시지는 동시 접속자 수와 상관 없이 푸시를 허용한 모든 유저에게 보내야 하고 쿼리 리팩토링 해야 하는 경우는 직원들이 대용량 데이터 처리 할 때 속도가 너무 나오지 않아 자주 했었다.)
하지만 경험상 대용량 트래픽을 처리 해 본 적이 없어서 (ㅠ__ㅠ...뭔가 하나 쯤은 잘 되었으면 해 봤을 텐데..)
몇가지 해결 방안들을 알고는 있는데...
공부도 할 겸 자료 조사를 하다가, Chat GPT한테도 몇가지 물어 봤다.
1. PHP-FPM을 커스텀 하여 서버 자체의 성능을 올리는 방법은 뭐야?
PHP 자체를 커스텀 해서 서버 자체의 성능을 올리는 방법은 솔직히 모르는 방법중에 하나였는데 이번에 어디선가 주워들어서..
GPT한테 물어보니 아래와 같은 답변을 해줬다.
- 프로세스 관리자 조정 PHP-FPM은 프로세스 관리자를 통해 프로세스의 수와 동작을 조정합니다. 이 관리자의 설정을 조정하여 성능을 최적화할 수 있습니다. 예를 들어, pm.max_children 값을 늘려서 동시에 처리할 수 있는 프로세스의 수를 늘릴 수 있습니다. 이렇게 함으로써 높은 트래픽을 처리할 때 대기 시간을 최소화할 수 있습니다.
- 메모리 관리 PHP-FPM은 메모리 사용량을 제한하는 것이 가능합니다. 이 설정을 조정하여 메모리 사용량을 최적화할 수 있습니다. 예를 들어, pm.max_requests 값은 일정 수 이상의 요청이 들어오면 프로세스를 다시 시작하여 메모리 누수를 방지할 수 있습니다.
- 캐싱 PHP-FPM은 캐싱을 통해 성능을 최적화할 수 있습니다. 예를 들어, opcache.enable 값을 true로 설정하여 PHP 코드를 캐싱할 수 있습니다. 이렇게 함으로써 PHP 코드를 컴파일할 필요 없이 더 빠른 실행 속도를 제공할 수 있습니다.
- 로깅 조정 PHP-FPM은 로그 기록을 통해 프로세스 동작 상황을 파악할 수 있습니다. 하지만 로그 기록을 자주 기록하게 되면 성능에 영향을 미칩니다. 로깅 레벨을 조정하거나, 로깅을 다른 파일로 분리하여 로깅 성능을 개선할 수 있습니다.
- 모듈 조정 PHP-FPM은 사용하는 모듈에 따라 성능이 달라질 수 있습니다. 따라서 필요하지 않은 모듈은 비활성화하여 성능을 최적화할 수 있습니다.
굉장히 제대로 된 답변을 준다..
2. 데이터 캐싱에서, 내가 생각한 방법이 진짜 좋은 방법이 맞어?
대용량 트래픽을 처리하기 위해서는 캐시 데이터를 사용하는 방법도 굉장히 좋은 방법이란건 안다.
Redis가 Hash 상태로 데이터를 저장하고, 이를 캐시하여 사용 할 수 있는 것도 알고 있다.
그러면, 뭔가 나름 정적인 데이터 (예를 들면 이번에 토이 프로젝트로 진행하고 있는 ArkInfo 쪽에서의 태그 리스트 라던가, 정적인 카테고리 리스트 라던가.. 카테고리의 경우에는 카테고리가 변경 될 때 마다 캐시 데이터를 갱신 시켜 주면 될 것이다.)
자체를 JSON 형태로 시리얼라이즈 시켜서 Redis에 저장하고 해당 내용을 캐시 처리하는건 실제로 좋은 방법일까?
redis에 json 데이터를 저장하고 php에서 cache 하는 방법은 좋은 방법일까?
라고 질문 해 보았다.
Redis에 JSON 데이터를 저장하고 PHP에서 캐시하는 것은 일반적으로 좋은 방법 중 하나입니다. Redis는 인메모리 데이터 저장소이므로 데이터를 빠르게 저장하고 불러올 수 있습니다. 또한, Redis는 다양한 데이터 형식을 지원하므로 JSON 데이터를 저장하는 것도 가능합니다.
PHP에서 Redis 캐시를 사용하면, Redis에 저장된 데이터를 빠르게 가져와서 처리할 수 있습니다. 이를 통해 PHP 애플리케이션의 성능을 향상시킬 수 있습니다. 또한, Redis는 다양한 기능을 제공하기 때문에, 예를 들어 TTL(Time To Live)을 설정하여 데이터를 만료시키는 등의 기능을 사용할 수도 있습니다.
하지만, Redis를 사용하는 것이 항상 좋은 방법은 아닙니다. Redis는 인메모리 데이터 저장소이기 때문에, 서버의 메모리를 많이 사용하게 됩니다. 따라서, Redis를 사용할 때는 서버의 메모리 용량을 고려하여 적절한 Redis 캐시 크기를 설정해야 합니다. 또한, Redis 서버가 단일 장애점(Single Point of Failure)이 될 수 있으므로, Redis 클러스터링이나 Redis Sentinel 등의 기술을 사용하여 고가용성을 보장해야 합니다.
마지막으로, Redis를 사용하는 것이 항상 좋은 방법인지는 상황에 따라 다릅니다. Redis를 사용하는 것이 적절한 경우도 있지만, 데이터 크기가 크거나 복잡한 쿼리를 처리해야 하는 경우에는 MySQL이나 MongoDB와 같은 데이터베이스를 사용하는 것이 더 적합할 수 있습니다. 따라서, 데이터의 특성과 요구사항을 고려하여 적절한 기술을 선택하는 것이 중요합니다.
질문을 해 보니 위와 같은 답변이 돌아왔다.
서버 메모리를 고려하여, 엄청 크지 않은 데이터를 직렬화 하여 캐싱시키는건 확실히 좋은 방법 일 것 같다.
3. 정적인 대용량 데이터가 존재 할 때, 해당 데이터를 페이지네이션 하여 가져와야 하는데.. 이를 캐싱으로 처리하려면?
음.. 이번에 토이 프로젝트를 하면서 약간 느낀건데, 게임 데이터상 정적이지만 대용량 데이터가 확연하게 존재 한다.
예를 들면 스토리 정보라던가.. 변경되지 않는 내용들이 있는데, 이를 페이지네이션 처리해서 가져오는게 확실한데..
이를 간단하게 구현 하려면 어떻게 해야 할까?
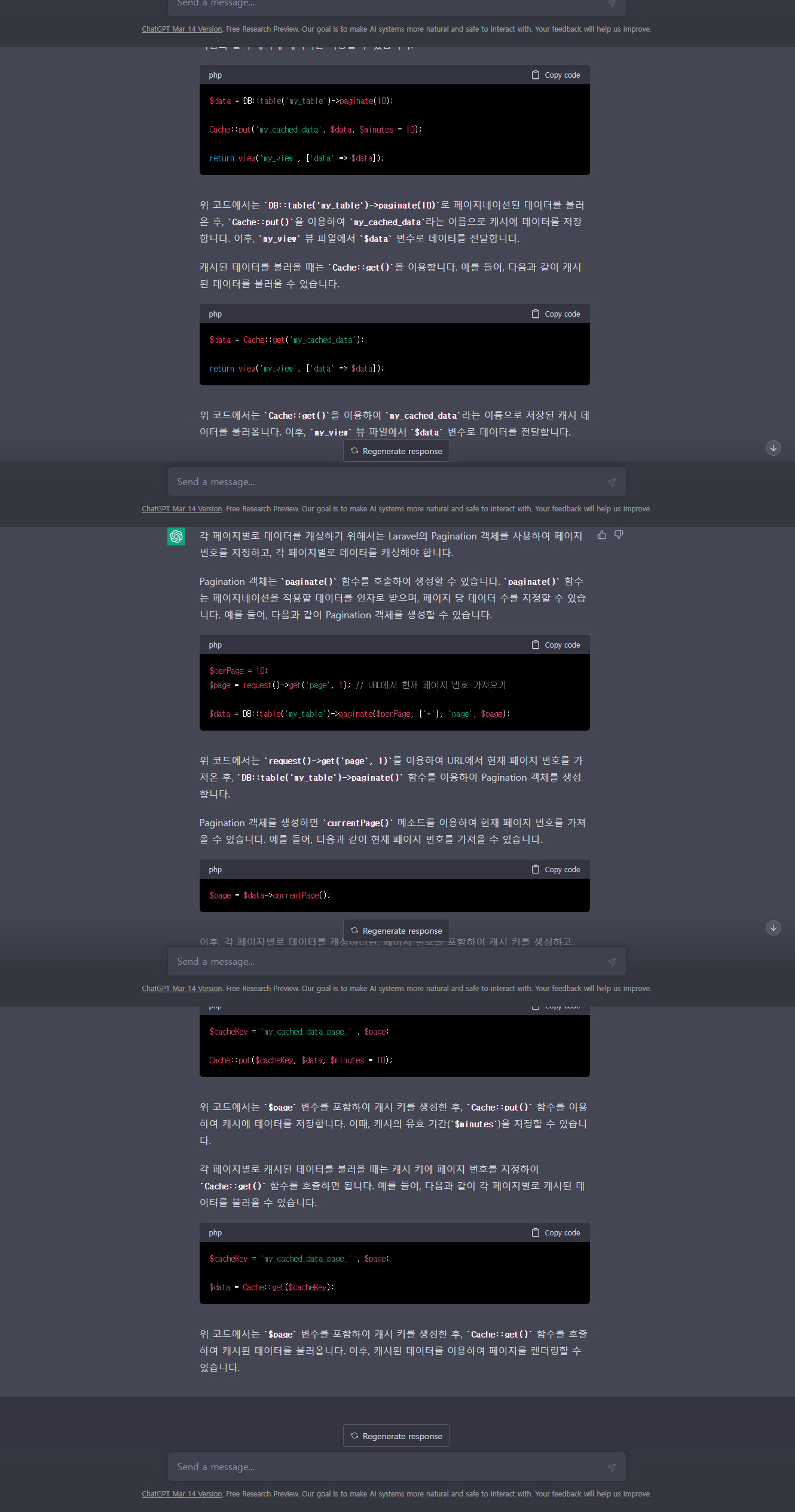
오우...
굉장히 잘 말해준다..
확실히, CHAT GPT는 개발에 크게 도움을 주는 것 같다.
앞으로 이런 인공지능을 어떻게 사용하는지에 따라서도 개발 시간이 많이 차이나게 될 것이다.
한가지, 결국엔 AI들도 웹에서 수집한 자료들을 토대로 대답할텐데
이에따른 정보 비용의 처리는 어떻게 할 것인가가.. 결국엔 해결해야 될 문제라고 생각된다.
얘가 이렇게 척척 말해주면 나중에는 아무도 블로그 같은데에 정리 하려고 안할테니..
어쨋든 오늘은 대용량 트래픽에 관련한 궁금증을 GPT와 함께 풀어보았다 ㅎ_ㅎ!
'Programming' 카테고리의 다른 글
| Laravel + hasura + postgresql - 기본 설정 (0) | 2023.12.05 |
|---|---|
| Oauth2.0 + API Server(Laravel Sanctum) + 통합인증 구현 (1) | 2023.08.30 |
| [Next.js] localstorage is not defined (0) | 2023.03.25 |
| [Next.js] Next.js Store redux (0) | 2023.03.23 |
| [Next.js] next/image 외부 이미지 이용시 Error: Invalid src prop (0) | 2023.03.22 |
PHP 에서 대용량 데이터를 처리하는데에 있어서 푸시 메시지를 보낼때 큐를 사용한다던가
기존 쿼리가 너무 좋지 않아 쿼리 리팩토링을 한다던가..
는 실제로 접해봐서 사용해 보긴 했는데 (푸시 메시지는 동시 접속자 수와 상관 없이 푸시를 허용한 모든 유저에게 보내야 하고 쿼리 리팩토링 해야 하는 경우는 직원들이 대용량 데이터 처리 할 때 속도가 너무 나오지 않아 자주 했었다.)
하지만 경험상 대용량 트래픽을 처리 해 본 적이 없어서 (ㅠ__ㅠ...뭔가 하나 쯤은 잘 되었으면 해 봤을 텐데..)
몇가지 해결 방안들을 알고는 있는데...
공부도 할 겸 자료 조사를 하다가, Chat GPT한테도 몇가지 물어 봤다.
1. PHP-FPM을 커스텀 하여 서버 자체의 성능을 올리는 방법은 뭐야?
PHP 자체를 커스텀 해서 서버 자체의 성능을 올리는 방법은 솔직히 모르는 방법중에 하나였는데 이번에 어디선가 주워들어서..
GPT한테 물어보니 아래와 같은 답변을 해줬다.
- 프로세스 관리자 조정 PHP-FPM은 프로세스 관리자를 통해 프로세스의 수와 동작을 조정합니다. 이 관리자의 설정을 조정하여 성능을 최적화할 수 있습니다. 예를 들어, pm.max_children 값을 늘려서 동시에 처리할 수 있는 프로세스의 수를 늘릴 수 있습니다. 이렇게 함으로써 높은 트래픽을 처리할 때 대기 시간을 최소화할 수 있습니다.
- 메모리 관리 PHP-FPM은 메모리 사용량을 제한하는 것이 가능합니다. 이 설정을 조정하여 메모리 사용량을 최적화할 수 있습니다. 예를 들어, pm.max_requests 값은 일정 수 이상의 요청이 들어오면 프로세스를 다시 시작하여 메모리 누수를 방지할 수 있습니다.
- 캐싱 PHP-FPM은 캐싱을 통해 성능을 최적화할 수 있습니다. 예를 들어, opcache.enable 값을 true로 설정하여 PHP 코드를 캐싱할 수 있습니다. 이렇게 함으로써 PHP 코드를 컴파일할 필요 없이 더 빠른 실행 속도를 제공할 수 있습니다.
- 로깅 조정 PHP-FPM은 로그 기록을 통해 프로세스 동작 상황을 파악할 수 있습니다. 하지만 로그 기록을 자주 기록하게 되면 성능에 영향을 미칩니다. 로깅 레벨을 조정하거나, 로깅을 다른 파일로 분리하여 로깅 성능을 개선할 수 있습니다.
- 모듈 조정 PHP-FPM은 사용하는 모듈에 따라 성능이 달라질 수 있습니다. 따라서 필요하지 않은 모듈은 비활성화하여 성능을 최적화할 수 있습니다.
굉장히 제대로 된 답변을 준다..
2. 데이터 캐싱에서, 내가 생각한 방법이 진짜 좋은 방법이 맞어?
대용량 트래픽을 처리하기 위해서는 캐시 데이터를 사용하는 방법도 굉장히 좋은 방법이란건 안다.
Redis가 Hash 상태로 데이터를 저장하고, 이를 캐시하여 사용 할 수 있는 것도 알고 있다.
그러면, 뭔가 나름 정적인 데이터 (예를 들면 이번에 토이 프로젝트로 진행하고 있는 ArkInfo 쪽에서의 태그 리스트 라던가, 정적인 카테고리 리스트 라던가.. 카테고리의 경우에는 카테고리가 변경 될 때 마다 캐시 데이터를 갱신 시켜 주면 될 것이다.)
자체를 JSON 형태로 시리얼라이즈 시켜서 Redis에 저장하고 해당 내용을 캐시 처리하는건 실제로 좋은 방법일까?
redis에 json 데이터를 저장하고 php에서 cache 하는 방법은 좋은 방법일까?
라고 질문 해 보았다.
Redis에 JSON 데이터를 저장하고 PHP에서 캐시하는 것은 일반적으로 좋은 방법 중 하나입니다. Redis는 인메모리 데이터 저장소이므로 데이터를 빠르게 저장하고 불러올 수 있습니다. 또한, Redis는 다양한 데이터 형식을 지원하므로 JSON 데이터를 저장하는 것도 가능합니다.
PHP에서 Redis 캐시를 사용하면, Redis에 저장된 데이터를 빠르게 가져와서 처리할 수 있습니다. 이를 통해 PHP 애플리케이션의 성능을 향상시킬 수 있습니다. 또한, Redis는 다양한 기능을 제공하기 때문에, 예를 들어 TTL(Time To Live)을 설정하여 데이터를 만료시키는 등의 기능을 사용할 수도 있습니다.
하지만, Redis를 사용하는 것이 항상 좋은 방법은 아닙니다. Redis는 인메모리 데이터 저장소이기 때문에, 서버의 메모리를 많이 사용하게 됩니다. 따라서, Redis를 사용할 때는 서버의 메모리 용량을 고려하여 적절한 Redis 캐시 크기를 설정해야 합니다. 또한, Redis 서버가 단일 장애점(Single Point of Failure)이 될 수 있으므로, Redis 클러스터링이나 Redis Sentinel 등의 기술을 사용하여 고가용성을 보장해야 합니다.
마지막으로, Redis를 사용하는 것이 항상 좋은 방법인지는 상황에 따라 다릅니다. Redis를 사용하는 것이 적절한 경우도 있지만, 데이터 크기가 크거나 복잡한 쿼리를 처리해야 하는 경우에는 MySQL이나 MongoDB와 같은 데이터베이스를 사용하는 것이 더 적합할 수 있습니다. 따라서, 데이터의 특성과 요구사항을 고려하여 적절한 기술을 선택하는 것이 중요합니다.
질문을 해 보니 위와 같은 답변이 돌아왔다.
서버 메모리를 고려하여, 엄청 크지 않은 데이터를 직렬화 하여 캐싱시키는건 확실히 좋은 방법 일 것 같다.
3. 정적인 대용량 데이터가 존재 할 때, 해당 데이터를 페이지네이션 하여 가져와야 하는데.. 이를 캐싱으로 처리하려면?
음.. 이번에 토이 프로젝트를 하면서 약간 느낀건데, 게임 데이터상 정적이지만 대용량 데이터가 확연하게 존재 한다.
예를 들면 스토리 정보라던가.. 변경되지 않는 내용들이 있는데, 이를 페이지네이션 처리해서 가져오는게 확실한데..
이를 간단하게 구현 하려면 어떻게 해야 할까?
오우...
굉장히 잘 말해준다..
확실히, CHAT GPT는 개발에 크게 도움을 주는 것 같다.
앞으로 이런 인공지능을 어떻게 사용하는지에 따라서도 개발 시간이 많이 차이나게 될 것이다.
한가지, 결국엔 AI들도 웹에서 수집한 자료들을 토대로 대답할텐데
이에따른 정보 비용의 처리는 어떻게 할 것인가가.. 결국엔 해결해야 될 문제라고 생각된다.
얘가 이렇게 척척 말해주면 나중에는 아무도 블로그 같은데에 정리 하려고 안할테니..
어쨋든 오늘은 대용량 트래픽에 관련한 궁금증을 GPT와 함께 풀어보았다 ㅎ_ㅎ!
'Programming' 카테고리의 다른 글
| Laravel + hasura + postgresql - 기본 설정 (0) | 2023.12.05 |
|---|---|
| Oauth2.0 + API Server(Laravel Sanctum) + 통합인증 구현 (1) | 2023.08.30 |
| [Next.js] localstorage is not defined (0) | 2023.03.25 |
| [Next.js] Next.js Store redux (0) | 2023.03.23 |
| [Next.js] next/image 외부 이미지 이용시 Error: Invalid src prop (0) | 2023.03.22 |